 Haskell is a great language for building embedded domain specific languages. Using algebraic data types and higher order functions, it’s very easy to work with and reason about an embedded language. This week at the ICFP, several people commented on how Haskell allowed them to build custom control structures and express ideas more clearly. However, while powerful, these embedded languages usually aren’t as expressive as their host language Haskell. The concrete syntax usually isn’t as succinct as the Haskell equivalent of a certain expression.
Haskell is a great language for building embedded domain specific languages. Using algebraic data types and higher order functions, it’s very easy to work with and reason about an embedded language. This week at the ICFP, several people commented on how Haskell allowed them to build custom control structures and express ideas more clearly. However, while powerful, these embedded languages usually aren’t as expressive as their host language Haskell. The concrete syntax usually isn’t as succinct as the Haskell equivalent of a certain expression.
This article explores the very early stages of an idea by Sebastiaan Visser and myself to more deeply embedding DSLs in Haskell. It has been written up rather quickly, so if (when?) you find errors, please do let me know. Also, when I say “early stages”, I really mean just that, there are lots of open questions and unknowns left. To start off, here’s a little teaser:
*Main> -- A simple function that operates on a generalized boolean
*Main> let f x = not x && false || true
*Main> -- Coerce the function to work on normal Prelude Bools
*Main> let g = f :: Prelude.Bool -> Prelude.Bool
*Main> -- Call the function
*Main> g false
True
*Main> -- Coerce the exact same function to work on JavaScript booleans
*Main let h = f :: Js JsBool -> Js JsBool
*Main> -- Call the function again
*Main> h false
(((false ? false : true) ? false : (false ? false : true))
? ((false ? false : true) ? false : (false ? false : true))
: true)
The JavaScript string above is the JavaScript equivalent of the f function applied to false. If we evaluate that string, we get a JavaScript boolean true!
> {-# LANGUAGE GADTs, FlexibleInstances, MultiParamTypeClasses, FunctionalDependencies #-}
Background
At its most basic level, a DSL is usually expressed as an ADT. Take for example this simple definition of a mathematical expression language:
> data ArithExpr
> = Lit Integer
> | Add ArithExpr ArithExpr
> | Mul ArithExpr ArithExpr
> | Sub ArithExpr ArithExpr
> deriving (Show, Eq)
With this evaluator:
> evalArith :: ArithExpr -> Integer
> evalArith (Lit x) = x
> evalArith (Add x y) = evalArith x + evalArith y
> evalArith (Mul x y) = evalArith x * evalArith y
> evalArith (Sub x y) = evalArith x - evalArith y
This is a very simple language supporting literal values (Lit), addition (Add), multiplication (Mul) and subtraction (Sub). Given this language, we can now write a mathematical expressions like “6 + 12 * 3” as such:
> a1 :: ArithExpr
> a1 = Add (Lit 6) (Mul (Lit 12) (Lit 3))
This is a bit verbose for something that can be expressed in Haskell with a lot less characters. But luckily, we can fix that in this case, by using the Num type class:
> instance Num ArithExpr where
> x + y = Add x y
> x * y = Mul x y
> x - y = Sub x y
> abs x = error "Not implemented"
> signum x = error "Not implemented"
> fromInteger x = Lit x
Now that we have made ArithExpr an instance of the Num type class, we can use Haskell syntax to write down ArithExpr expressions:
> a2 :: ArithExpr
> a2 = 6 + 12 * 3
Of course, while this looks like a Haskell epression, it still generates an ArithExpr expression tree:
ghci> a2
Add (Lit 6) (Mul (Lit 12) (Lit 3))
Getting functions for free
Now that our ArithExpr is an instance of Num we can use functions like +, but we can do even more. We can also reuse all existing functions that are defined in terms of the + operator and other functions in the Num type class. For example the sum function:
sum :: (Num a) => [a] -> a
sum [] = fromInteger 0
sum (x:xs) = x + sum xs
Since this function is defined entirely using functions from the Num type class, it also works on our ArithExpr!
> a3 :: ArithExpr
> a3 = sum [3, 4 * 3, 2 - 7]
When we inspect this in GHCi we get the following:
ghci> a3
Add (Add (Add (Lit 0) (Lit 3)) (Mul (Lit 4) (Lit 3)))
(Sub (Lit 2) (Lit 7))
ghci> evalArith a3
10
Obviously we didn’t just add lists to our simple expression language. The lists here are Haskell lists, containing ArithExpr values. Haskell can be used as a meta programming language for the ArithExpr language.
Scaling up: using more Haskell syntax
A few months ago Sebastiaan send a message to the Haskell Cafe mailing list titled “Bool as type class to serve EDSLs” where he asked about using the Eq type class for DSLs. In the same way that we make ArithExpr an instance of Num. Lets take this ADT:
> data Expr a where
> Num :: ArithExpr -> Expr Integer
> LitFalse :: Expr Bool
> LitTrue :: Expr Bool
> Equal :: Expr Integer -> Expr Integer -> Expr Bool
> If :: Expr Bool -> Expr a -> Expr a -> Expr a
The Eq and Show instances for this GADT are provided at the end of this article. The evaluator is defined as such:
> eval :: Expr a -> a
> eval (Num ae) = evalArith ae
> eval (LitFalse) = False
> eval (LitTrue) = True
> eval (Equal e1 e2) = eval e1 == eval e2
> eval (If p e1 e2) = if eval p then eval e1 else eval e2
We can now write down an expression like this:
> a4 :: Expr Integer
> a4 = If (Equal ((2 + 3)) (5))
> (Num 1)
> (Num 0)
And here’s where the Eq type class comes in, we’d like to use the (==) operator instead of the Equal constructor. Unfortunately, this is not possible since the type of (==) is this:
(==) :: Eq a => a -> a -> Bool
This shows us that (==) is polymorphic in both its arguments, but not in its return type. We could make our Expr data type an instance of Eq, but won’t be not able to use Equal as an implementation of (==). Equal is of type Expr Integer -> Expr Integer -> Expr Bool, it returns a Expr Bool instead of Bool.
What we would like to have is a more polymorphic (==) of the following type:
(==) :: (Eq a, BooleanLike b) => a -> a -> b
We have replaced the type Bool with a polymorphic b that is an instance of the BooleanLike type clas. This way (==) is polymorphic in both its arguments (a long as they implement Eq) and its result type (as long as its “BooleanLike“).
In other words: we replace the concrete data type Bool with a polymorphic type b in a type class. Can we take this further?
Going large: no more data types!
With that idea in mind (replace data types with type classes), Sebastiaan and I have been working on systematically rewriting the Haskell Prelude to a more general version. We have dubbed this alternative Prelude the AwesomePrelude, and it’s currently available on github.
Lets have a look at how the AwesomePrelude works. First the normal Prelude Bool data type:
data Bool = False | True
This is rewritten in the AwesomePrelude to the following type class (called Bool in the AwesomePrelude):
> class Boolean f r | f -> r where
> bool :: r -> r -> f -> r
> false :: f
> true :: f
This type class consists of these parts:
- The
false and true members. These represent the original two constructors, but they now are more polymorphic, since they are of type f, the first argument to the type class.
- The
bool function. Because we no longer have real constructors (we use true and false), we can’t do pattern matching anymore. With bool we can “fold” over a Bool value. The bool function destructs a f value and it returns either the first (false) argument or the second (true) argument.
- The
f type argument. This is the concrete type we use to represent a boolean. In the case of our Expr data type, this is (Expr Bool), see below.
- The
r type argument and f -> r functional dependency. This is the somewhat strange part of the type class. We’ll discuss this after we’ve looked at the Expr instance.
Giving the type class defined above, we make our Expr data type an instance of the type class like so:
> instance Boolean (Expr Bool) (Expr Integer) where
> bool f t p = If p f t
> false = LitFalse
> true = LitTrue
This instance demonstrates the need for the r type argument in the Boolean type class. The r variable is the type to which a boolean is “destructed”, when it is “pattern matched” (that is, it is used). We need a way to ensure that the result of using a boolean in a DSL doesn’t fall outside that DSL.
In the case of our Expr data type, the result of If can only be a Expr Integer. Other languages might be a bit more liberal, but they usually do at restrictions. For example, we provide a JavaScript instance of the AwesomePrelude called JsPrelude. In this JsPrelude, we have this: instance Boolean (Js Bool) (Js a). That means that using a Js Bool will always result in a Js a.
To show how this pattern generalizes, lets look at the Maybe type class.
class Maybe f a r | f -> a, f -> r where
maybe :: r -> (a -> r) -> f a -> r
nothing :: f a
just :: a -> f a
This type class again has two “constructors”, nothing and just. Also there is a “destructor” function called maybe, which happens to be the same thing as the maybe function in the normal Haskell Prelude.
The real difference between the Maybe type class and the Bool type class is the extra type variable a. This is introduced because the normal Maybe data type has a type variable a. Indeed, the number of type variables in the “type classification” of a data type is equal to its original number of arguments plus two for the f and the r
Conclusion? Free functions and future work!
We are currently working on the AwesomePrelude on github. The AwesomePrelude module exposes type classes for each data type in the normal Prelude. Note that by “each”, I really mean “the five that we felt like writing”. The AwesomePrelude module also exports common functions like (&&), sum and uncurry, that are entirely defined in terms of the “constructors” and “destructors” in the module.
We have written a JsPrelude that provides instances for the type classes defined in the AwesomePrelude. While this module is far from complete (we’re doing some weird type hackery, that isn’t really working), it can already do some cool things, like the example at the top of this article.
… define a function on “type class values” in the exact same way as on normal “data type values” … there is no difference between using the generalized functions and the original functions.
The Main module shows some examples of uses of the generalized Prelude. The nice point about this examples is this though: We can define a function on “type class values” in the exact same way as we would on normal “data type values”. Except for constructors and pattern matching, there is no difference between using the generalized functions and the original functions.
To sum up: Our understanding of this concept is still currently rather limited, but I have the feeling we can do a lot with this, particularly in the field of embedded domain specific languages. After seeing a couple of interesting talks this week at the ICFP and the Haskell Symposium, I think I need to start reading lots of papers (any pointers would be appreciated). More on this to follow!
A few remaining instance declarations:
> instance (Show a) => Show (Expr a) where
> show (Num ae) = "Num (" ++ show ae ++ ")"
> show (LitFalse) = "LitFalse"
> show (LitTrue) = "LitTrue"
> show (Equal e1 e2) = "Equal (" ++ show e1 ++ ") (" ++ show e2 ++ ")"
> show (If p e1 e2) = "If (" ++ show p ++ ") (" ++ show e1 ++ ")"
> ++ " (" ++ show e2 ++ ")"
> instance (Eq a) => Eq (Expr a) where
> (Num ae) == (Num ae') = ae == ae'
> (LitFalse) == (LitFalse) = True
> (LitTrue) == (LitTrue) = True
> (Equal e1 e2) == (Equal e1' e2') = e1 == e1' && e2 == e2'
> (If p e1 e2) == (If p' e1' e2') = p == p' && e1 == e1'
> && e2 == e2'
> _ == _ = False
> instance Num (Expr Integer) where
> (Num x) + (Num y) = Num (x + y)
> (Num x) * (Num y) = Num (x * y)
> abs (Num x) = Num (abs x)
> signum (Num x) = Num (signum x)
> fromInteger x = Num (Lit x)
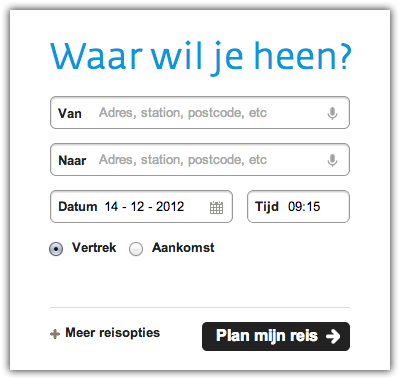 Begin dit jaar begonnen we met
Begin dit jaar begonnen we met 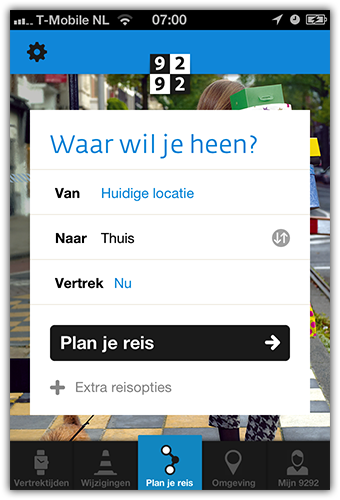 De iPhone app begint heel prominent met een vraag “Waar wil je heen?”. We wilden het daadwerkelijk plannen van een reis zo dicht mogelijk brengen bij het antwoord van de gebruiker op die vraag. Dus je vult enkel het ‘Naar’ adres in (bijvoorbeeld ‘Thuis’ uit je favorieten), en dan plannen we de snelste reis naar huis met het OV. Om te kunnen plannen met maar 1 invoer moeten we default waarden kiezen voor overige velden. Dat was niet moeilijk voor de vertreklocatie, de iPhone heeft een GPS sensor, dus we kunnen je huidige locatie als vertrekpunt nemen. Het kiezen van een default voor het tijdstip was iets meer denkwerk.
De iPhone app begint heel prominent met een vraag “Waar wil je heen?”. We wilden het daadwerkelijk plannen van een reis zo dicht mogelijk brengen bij het antwoord van de gebruiker op die vraag. Dus je vult enkel het ‘Naar’ adres in (bijvoorbeeld ‘Thuis’ uit je favorieten), en dan plannen we de snelste reis naar huis met het OV. Om te kunnen plannen met maar 1 invoer moeten we default waarden kiezen voor overige velden. Dat was niet moeilijk voor de vertreklocatie, de iPhone heeft een GPS sensor, dus we kunnen je huidige locatie als vertrekpunt nemen. Het kiezen van een default voor het tijdstip was iets meer denkwerk.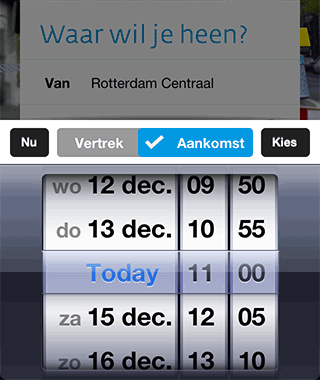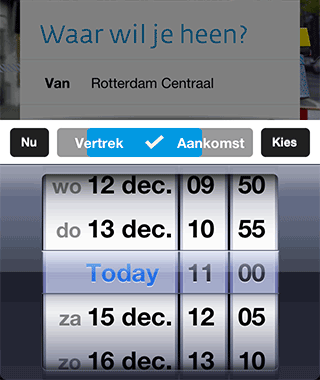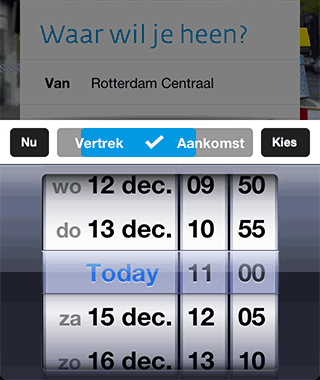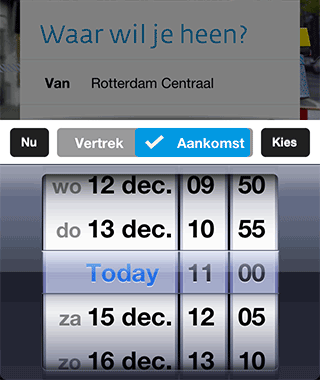 Als je op dat veld tapt verschijnt er een datepicker. Rechtsboven zit een Kies-knop waarmee je je selectie kunt bevestigen. Links boven zit een Nu-knop. Deze stelt ‘Vertrek nu’ in en sluit de ‘datepicker’ ook weer. Tussen die twee knoppen zit de keuze voor ‘Vertrek’ of ‘Aankomst’. Hiervoor wilden we geen toggle button met twee kleuren maken, omdat het dan moeilijk is om te zien welke van de twee geselecteerd is.
Als je op dat veld tapt verschijnt er een datepicker. Rechtsboven zit een Kies-knop waarmee je je selectie kunt bevestigen. Links boven zit een Nu-knop. Deze stelt ‘Vertrek nu’ in en sluit de ‘datepicker’ ook weer. Tussen die twee knoppen zit de keuze voor ‘Vertrek’ of ‘Aankomst’. Hiervoor wilden we geen toggle button met twee kleuren maken, omdat het dan moeilijk is om te zien welke van de twee geselecteerd is.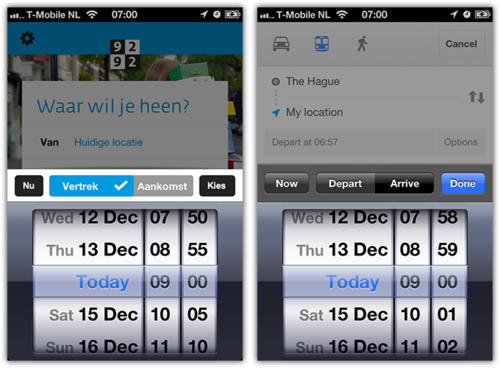

 The Haskell community is very active. New packages are released to the central
The Haskell community is very active. New packages are released to the central