TLDR; Use lazy evaluation to prevent high coupling.
There are two ways to design an application: based a particular framework, or using libraries.
Actually, there are a lot more ways to build applications, including combinations of the two, but let’s just focus on those.
First, let’s define the word “framework”. I want to set it apart from what’s known as a platform.
A platform is some lowest level on which to build an application, examples are OS’s or virtual machines, e.g.: Linux, OS X, Java, or .NET.
These platforms are great; They allow application developers to focus on the specific application logic, reusing all the ‘plumbing’ like sockets and file systems.
No, what I mean by frameworks, are the things your application (or part of your application) lives in.
Examples of such a frameworks are Java’s Swing, or ASP.NET MVC.
Differences between a framework and a library
There are, of course, a lot of definitions of frameworks and libraries. I don’t want to get into those, rather I’d like to illustrate my view on the differences by means of this picture:
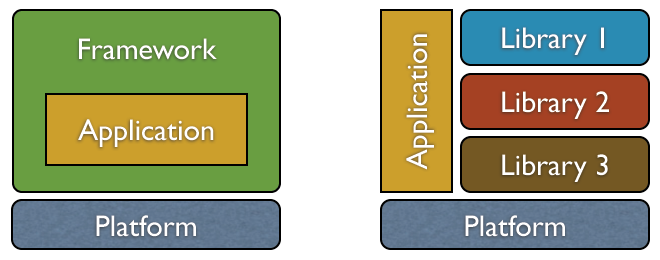
When building an application using a particular framework, the application lives inside the framework.
This is most noticeable when the application is required to inherit from some framework class, although this is not always the case.
From the viewpoint of the application, the framework is the whole world.
The framework is the all-powerful environment which can do everything the application would ever want (for some particular domain, at least).
Alternatively, an application can be writing using libraries (and it’s always libraries, plural, it’s never just the one).
In that design, a library is just tacked on to the side of the application.
The application stands on its own, it has an identity outside of a particular framework, and it just uses libraries to do some part of the work.
Benefits of a framework
On his blog, Martin Fowler describes “Inversion of Control” as perhaps the “defining characteristic of a framework”.
Wikipedia also mentions inversion of control, along with default behaviour and extensibility, as one of the distinguishing features of a framework.
Inversion of control, also known as the Hollywood Principle “Don’t call us, we’ll call you”, can indeed be a benefit.
An example of this is a graphical (web) application that renders some data.
In this example, the framework is responsible for rendering the data to the end-user. Thus the application might not know how much data is required or when to compute it.
By having the framework call application code, it can ask for data when it is needed, and only ask for as much data as can currently be displayed.
Martin describes this better than I can:
Inversion of Control is a key part of what makes a framework different to a library. A library is essentially a set of functions that you can call, these days usually organized into classes.
Each call does some work and returns control to the client.A framework embodies some abstract design, with more behavior built in. In order to use it you need to insert your behavior into various places in the framework either by subclassing or by plugging in your own classes.
The framework’s code then calls your code at these points.
Downsides of a framework
I’ve already alluded to some of the downsides I think frameworks have.
First of all, frameworks require a lot from client code. In some OO frameworks the application is required to implement an interface, or worse, to inherit from a framework baseclass.
An example of this is Swing, the Java GUI framework, where you’re supposed to create a subclass of JComponent.
When you do this, you can call the framework (e.g. super.getX()), and the framework can call you back, for example if you override the paint method.
However, by using this design you’ve just giving up the only inheritance mechanism you have in Java!
Say goodbye to all your nice object oriented designs.
Frameworks are also notoriously hard to replace. Precisely because the framework is the application’s whole world.
If you’re using an encryption library you don’t like, you can replace it by some other one.
In frameworks, this is not the case, you can’t just replace a framework.
The best you can hope for is to just add a new encryption library, bypassing the capabilities build-in to the framework.
Granted, replacing a library might be some work, since the API’s for the different libraries can be quite different, but it’s probably doable.
The same, hard-to-replace argument can be used against platforms, but there I think it’s less applicable.
An application usually is better, the more native to the platform it feels (and is).
For example, a native OS X application usually works a lot better than something that barely uses OS X’s capabilities.
An application that uses more of a framework doesn’t feel more native, it just feels more default.
The biggest problem I have with frameworks is the tight coupling between the application and the framework.
The application calls the framework to do certain things, and the framework calls the application back.
This tight coupling goes directly against well known software design principles, and it is the ultimate source of the problems described above.
Alternative to a framework
Ok, so that are some of the benefits and downsides to frameworks, but what is a good alternative to a framework? Well, libraries of course!
Here we come to the issue of programming languages. If your language is powerful enough, you can build libraries with the same capabilities as frameworks.
By using higher-order functions, you can pass in code to the library to execute when it needs it.
Some might say that such a library is now a framework, but I wouldn’t call the map function a whole framework. I certainly don’t live in map.
So, using higher-order functions you can replace some of the capabilities of a framework in a library, but that still doesn’t feel right.
If your library uses a lot of higher-order functions, you might get the same functionalities as a framework, but now your code is all written inside-out.
The solution to this issue is lazy evaluation.
In a lazy-by-default language like Haskell, an application can just pass in a (potentially) giant data structure to a rendering library.
The library will only consume as much of the data structure as it needs, and no further evaluation will be done.
In other words; Lazy evaluation uncouples the data producer from the data consumer.
Sure there’s still the need to communicate about how much data is needed, but this is taken care of by the runtime system.
There doesn’t need to be an intimate dialog between a framework and the application about which data is needed and when.
The first example some people give when explaining lazy evaluation is “now you can create an infinite list of prime numbers!”, but who needs that?
I think lazy evaluation brings something that’s way more important, that is a fundamental part of software design; Lazy evaluation gives you composability.
Composability

“LEGO” photograph, by Jez Page.
The silver bullet in software development is composability. Or, if you don’t belief in silver bullets, let’s just agree its a step in the Right Direction.
The old idea of building software out of separate parts, like Lego blocks is still appealing.
However, the fact that there are so many frameworks out there shows that there is a need for something more than “blocks”.
I think the parts we need to build up larger and more complex applications are not shaped like rectangular blocks.
The “components” of the future will make heavy use of lazy evaluation and higher-order functions to allow for better composability.
By writing libraries from the core up to make extensive use of lazy evaluation and higher-order functions, we get reusable, composable, loosely coupled components.
These libraries are way more reusable than any framework, and they will lead to better designed applications.
Conclusion
In conclusion, I think the benefits frameworks have over traditional libraries do not outweigh the costs.
Using sufficiently powerful programming languages, we can create better libraries that use lazy evaluation and higher-order functions.
The only downside that properly designed libraries have to frameworks is that they are way harder to build.
A framework can basically be created by taking any old application, removing the content, putting in some hooks to call back to client code, and now you have a framework!
(That’s perhaps a bit of an oversimplification, but I like to beat up on frameworks ;-).)
Libraries on the other hand need to be designed, they need a good and clean API, otherwise they’re unusable.
On the upside, while frameworks often need the be “learned”, this is less so the case with libraries.
People read whole books on how to use a particular framework, but they usually just start programming against a library.
Again, I think the costs of a framework are bigger than the benefits it has.
Especially now that more and more libraries begin using lazy evaluation and higher-order functions. Particularly in languages like Haskell.
The future of software components is libraries.
Or, to put this article in other words: Haskell people, please stop building “frameworks”, we’re better than that!
 Haskell is a great language for building embedded domain specific languages. Using algebraic data types and higher order functions, it’s very easy to work with and reason about an embedded language. This week at the ICFP, several people commented on how Haskell allowed them to build custom control structures and express ideas more clearly. However, while powerful, these embedded languages usually aren’t as expressive as their host language Haskell. The concrete syntax usually isn’t as succinct as the Haskell equivalent of a certain expression.
Haskell is a great language for building embedded domain specific languages. Using algebraic data types and higher order functions, it’s very easy to work with and reason about an embedded language. This week at the ICFP, several people commented on how Haskell allowed them to build custom control structures and express ideas more clearly. However, while powerful, these embedded languages usually aren’t as expressive as their host language Haskell. The concrete syntax usually isn’t as succinct as the Haskell equivalent of a certain expression. The Haskell community is very active. New packages are released to the central
The Haskell community is very active. New packages are released to the central 